
|
[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index] Re: [Xen-devel] Create a iSCSI DomU with disks in another DomU running on the same Dom0
On Fri, Jan 11, 2013 at 04:57:52PM +0100, Roger Pau Monné wrote:
> Hello Konrad,
>
> I've found the problem, blkback is adding granted pages to the bio that
> is then passed to the underlying block device. When using a iscsi
> target running on another DomU in the same h/w this bios end up in
> netback, and then when performing the gnttab copy operation, it
> complains because the passed mfn belongs to a different domain.
OK, so my original theory was sound. The m2p override "sticks".
>
> I've checked this by applying the appended patch to blkback, which
> allocates a buffer to pass to the bio instead of using the granted
> page. Of course this should not applied, since it implies additional
> memcpys.
>
> I think the right way to solve this would be to change netback to
> use gnttab_map and memcpy instead of gnttab_copy, but I guess this
> will imply a performance degradation (haven't benchmarked it, but I
> assume gnttab_copy is used in netback because it is faster than
> gnttab_map + memcpy + gnttab_unmap).
Or blkback is altered to use grant_copy. Or perhaps m2p_override
can do multiple PAGE_FOREIGN? (So if it detects a collision it will
do something smart.. like allocate a new page or update the
kmap_op with extra information).
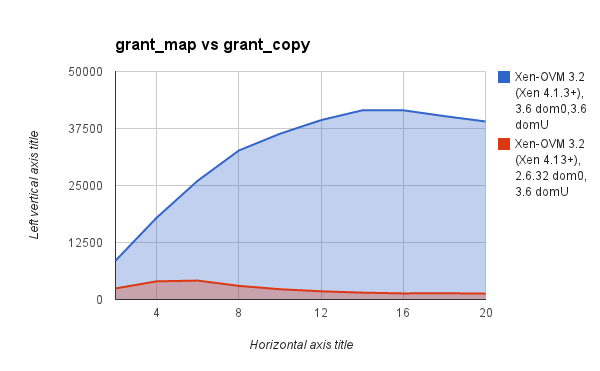
And yes, grant_map in netback is much much slower that grant_copy
(I tested 2.6.32 vs 3.7 using a Xen 4.1.3 with the grant_copy fixes
that Jan came up with).
See attached.
>
> ---
>
> diff --git a/drivers/block/xen-blkback/blkback.c
> b/drivers/block/xen-blkback/blkback.c
> index 8808028..9740cbb 100644
> --- a/drivers/block/xen-blkback/blkback.c
> +++ b/drivers/block/xen-blkback/blkback.c
> @@ -80,6 +80,8 @@ struct pending_req {
> unsigned short operation;
> int status;
> struct list_head free_list;
> + struct page *grant_pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + void *bio_pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> DECLARE_BITMAP(unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
> };
>
> @@ -701,6 +703,7 @@ static void xen_blk_drain_io(struct xen_blkif *blkif)
>
> static void __end_block_io_op(struct pending_req *pending_req, int error)
> {
> + int i;
> /* An error fails the entire request. */
> if ((pending_req->operation == BLKIF_OP_FLUSH_DISKCACHE) &&
> (error == -EOPNOTSUPP)) {
> @@ -724,6 +727,16 @@ static void __end_block_io_op(struct pending_req
> *pending_req, int error)
> * the proper response on the ring.
> */
> if (atomic_dec_and_test(&pending_req->pendcnt)) {
> + for (i = 0; i < pending_req->nr_pages; i++) {
> + BUG_ON(pending_req->bio_pages[i] == NULL);
> + if (pending_req->operation == BLKIF_OP_READ) {
> + void *grant =
> kmap_atomic(pending_req->grant_pages[i]);
> + memcpy(grant, pending_req->bio_pages[i],
> + PAGE_SIZE);
> + kunmap_atomic(grant);
> + }
> + kfree(pending_req->bio_pages[i]);
> + }
> xen_blkbk_unmap(pending_req);
> make_response(pending_req->blkif, pending_req->id,
> pending_req->operation, pending_req->status);
> @@ -846,7 +859,6 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> int operation;
> struct blk_plug plug;
> bool drain = false;
> - struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>
> switch (req->operation) {
> case BLKIF_OP_READ:
> @@ -889,6 +901,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> pending_req->operation = req->operation;
> pending_req->status = BLKIF_RSP_OKAY;
> pending_req->nr_pages = nseg;
> + memset(pending_req->bio_pages, 0, sizeof(pending_req->bio_pages));
>
> for (i = 0; i < nseg; i++) {
> seg[i].nsec = req->u.rw.seg[i].last_sect -
> @@ -933,7 +946,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> * the hypercall to unmap the grants - that is all done in
> * xen_blkbk_unmap.
> */
> - if (xen_blkbk_map(req, pending_req, seg, pages))
> + if (xen_blkbk_map(req, pending_req, seg, pending_req->grant_pages))
> goto fail_flush;
>
> /*
> @@ -943,9 +956,17 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> xen_blkif_get(blkif);
>
> for (i = 0; i < nseg; i++) {
> + void *grant;
> + pending_req->bio_pages[i] = kmalloc(PAGE_SIZE, GFP_KERNEL);
> + if (req->operation == BLKIF_OP_WRITE) {
> + grant = kmap_atomic(pending_req->grant_pages[i]);
> + memcpy(pending_req->bio_pages[i], grant,
> + PAGE_SIZE);
> + kunmap_atomic(grant);
> + }
> while ((bio == NULL) ||
> (bio_add_page(bio,
> - pages[i],
> + virt_to_page(pending_req->bio_pages[i]),
> seg[i].nsec << 9,
> seg[i].buf & ~PAGE_MASK) == 0)) {
>
>
>
Attachment:
grant_copy_vs_grant_map.png _______________________________________________ Xen-devel mailing list Xen-devel@xxxxxxxxxxxxx http://lists.xen.org/xen-devel
|
 |
Lists.xenproject.org is hosted with RackSpace, monitoring our |
{kind=link}